Abstract
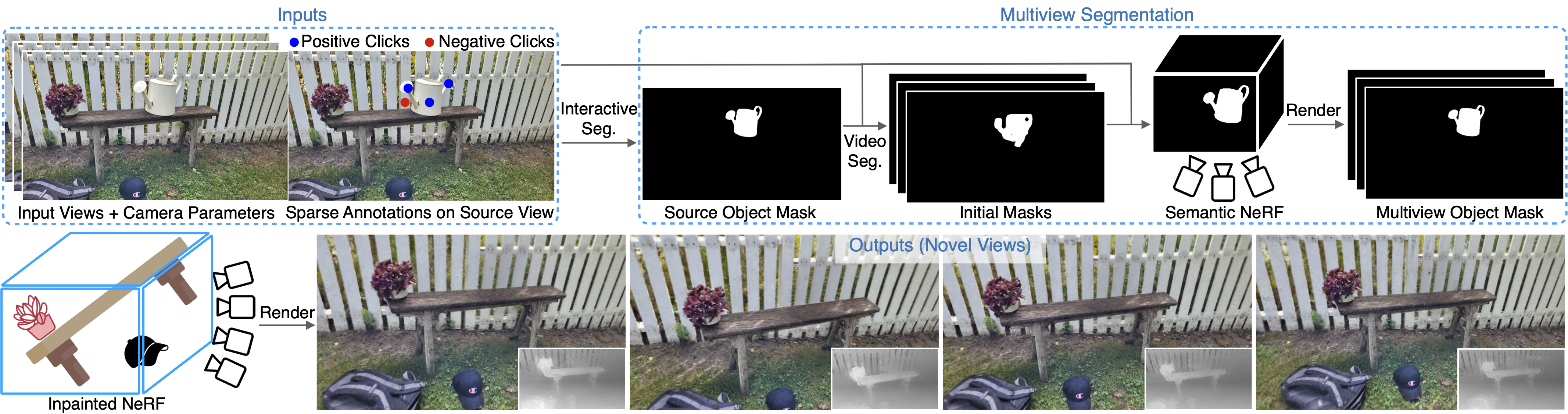
Neural Radiance Fields (NeRFs) have emerged as a popular approach for novel view synthesis. While NeRFs are quickly being adapted for a wider set of applications, intuitively editing NeRF scenes is still an open challenge. One important editing task is the removal of unwanted objects from a 3D scene, such that the replaced region is visually plausible and consistent with its context. We refer to this task as 3D inpainting. In 3D, solutions must be both consistent across multiple views and geometrically valid. In this paper, we propose a novel 3D inpainting method that addresses these challenges. Given a small set of posed images and sparse annotations in a single input image, our framework first rapidly obtains a 3D segmentation mask for a target object. Using the mask, a perceptual optimization-based approach is then introduced that leverages learned 2D image inpainters, distilling their information into 3D space, while ensuring view consistency. We also address the lack of a diverse benchmark for evaluating 3D scene inpainting methods by introducing a dataset comprised of challenging real-world scenes. In particular, our dataset contains views of the same scene with and without a target object, enabling more principled benchmarking of the 3D inpainting task. We first demonstrate the superiority of our approach on multiview segmentation, comparing to NeRF-based methods and 2D segmentation approaches. We then evaluate on the task of 3D inpainting, establishing state-of-the-art performance against other NeRF manipulation algorithms, as well as a strong 2D image inpainter baseline.
Video
Inpainting Pipeline
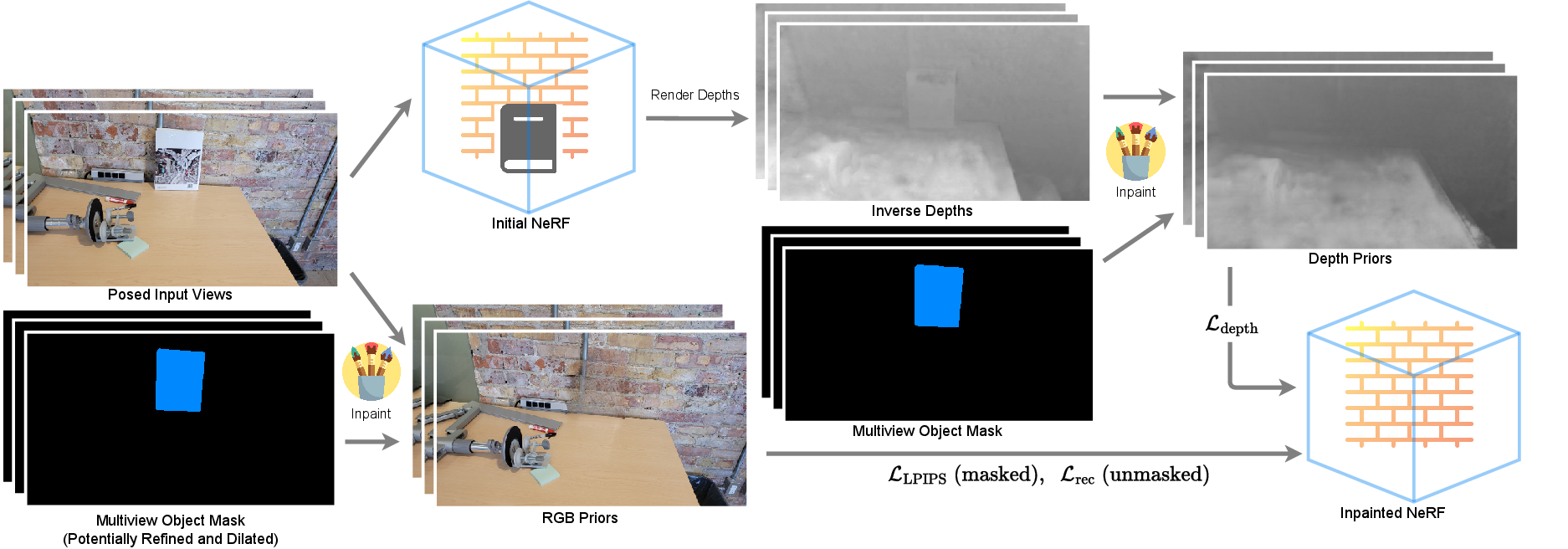
An overview of our proposed inpainting pipeline. Using the posed input images and their corresponding masks (upper and lower left insets), we obtain (i) an initial NeRF with the target object present and (ii) the set of inpainted input RGB images with the target object removed (but with view inconsistencies). The initial NeRF (i) is used to compute depth values, which we inpaint to obtain depth images as geometric priors (upper-right inset). The inpainted RGB images (ii), which act as appearance priors, are used in conjunction with the depth priors, to fit a 3D consistent NeRF to the inpainted scene (lower-right inset).


